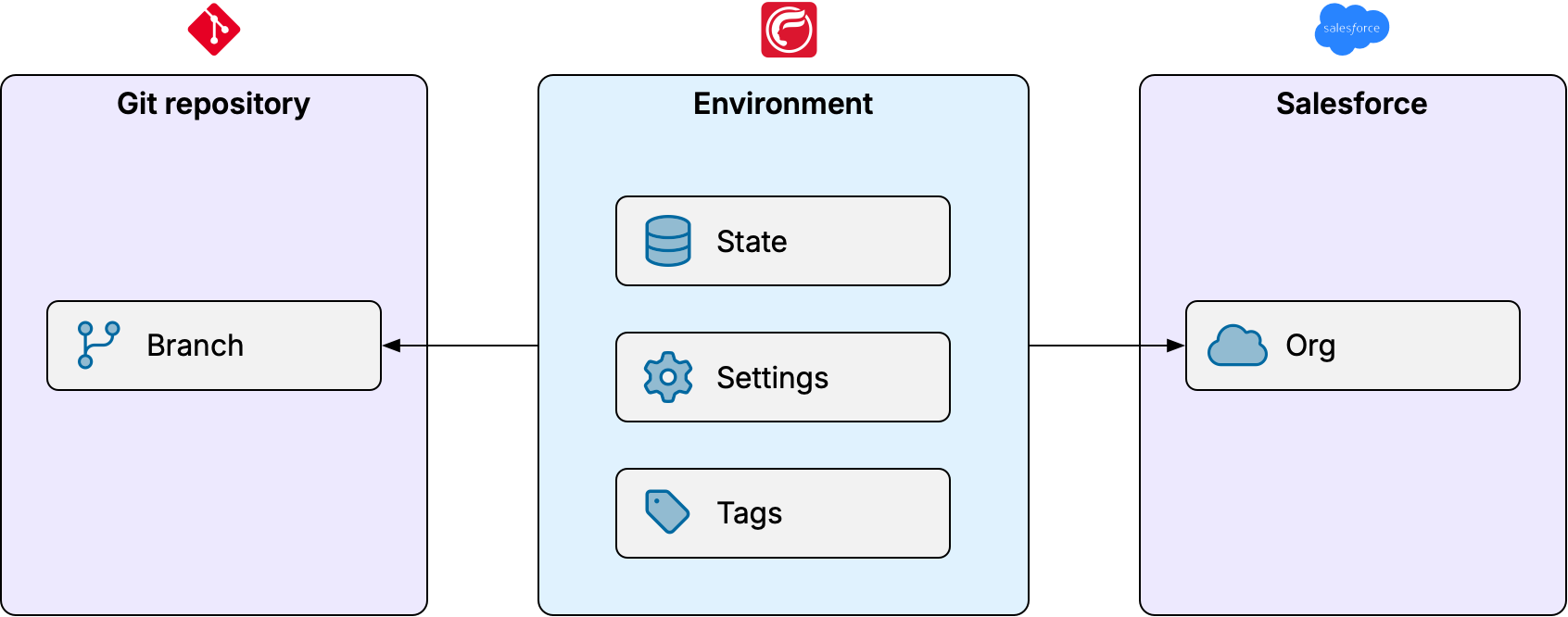
Environments
An environment is a configured connection between a Salesforce org and a branch in your Git repository. It's used to keep the metadata in the Salesforce org and the Git branch in sync, by flowing metadata changes from org to branch (retrieving) and from branch to org (deploying). It's also used to flow metadata changes between different environments in the stack (merging).
An environment consists of:
- The name of a branch in your Git repository
- Connection settings for a Salesforce org (production or sandbox)
- API version selection settings
- Tags
- State to keep track of the metadata flow
Production environment
The production environment is simply the environment connected to your Salesforce production org. There must be exactly one production environment in the stack. The production environment is typically connected to the main or master branch in your repository.
The production environment plays a key role in OrgFlow, but only because it's used to create and manage sandboxes. For purposes of metadata change flow and deployment, OrgFlow makes no practical distinction between your production environment and other environments.
This means you are free to make changes directly in your production org, and push commits directly to your main branch, if you decide that's appropriate. Many teams choose to avoid making changes directly in production as a matter of risk management. OrgFlow, however, fully supports flowing changes both downstream and upstream, and imposes no such restrictions.
From a business standpoint, your production org is of course treated with greater care and caution. Your production org is also normally considered the "single source of truth" whenever non-mergeable differences need to be reconciled, either between your production org and your main branch or between your production environment and sandbox environments.
Sandbox environments
As the name implies, sandbox environments are environments connected to Salesforce sandboxes. Sandbox environments are technically optional — there can be zero or more sandbox environments in the stack — but typically you will want some sandboxes in your stack in order to flow metadata changes between environments and get any meaningful DevOps work done.
Structuring sandboxes
You can create and manage as many sandbox environments in your stack as your Salesforce license supports and your workspace subscription limits allow. How frequently you create your sandbox environments, how you structure and name them, how you flow changes between them, when you delete them etc. is entirely up to you.
Some example strategies include:
- Sandbox per user story
- Sandbox per larger project
- Sandbox per developer
- Sandbox for a particular purpose such as staging or user acceptance testing
- Dedicated sandbox for hotfixes
- A mix of the above
Sandboxes are atomic
In OrgFlow, changes are always flowed between environments by merging between Git branches — never as arbitrary copy/paste operations of individual files or metadata components.
This brings a multitude of benefits: detailed change history, the ability to revert or roll back changes, automatic change detection, conflict detection and resolution — just to name a few. It also imposes an important restriction: all metadata changes made in a sandbox environment (and committed to its branch) are always merged to another environment as a single cohesive unit of change.
Properly managed, this constraint is a huge advantage. It removes the tedious and error prone task of figuring out which changes depend on which other changes, in order to create a cohesive set of changes that will successfully deploy.
You should always consider each sandbox environment atomic in terms of flowing metadata changes to other environments, and use the following rule-of-thumb to decide how to assign development efforts between sandboxes:
- If two changes are inextricably linked (i.e. depend on each other, must be deployed together) they should be made in the same sandbox environment
- If two changes are potentially independent (i.e. may need to be deployed at different times) they should be made in two different sandbox environments
The second point is particularly important. For example, consider the following scenario:
- Your team starts developing feature A and feature B in sandbox ROMEO
- Features A and B are merged (atomically) into sandbox TEST
- User acceptance testing is conducted in TEST
- Feature A is accepted, but feature B is deemed not ready for release
- Because features A and B come from the same sandbox and have been committed to the same Git branch, they can no longer be easily separated
- Feature B is now blocking release of feature A
Sandbox lifetime
Environments can technically be short-lived or long-lived, depending on your needs.
The longer a sandbox environment lives, the further it will inevitably drift from your production environment (and from other sandbox environments) in terms of data, users and groups, as well as metadata you have chosen to not include in the flow. Moreover, even if you regularly merge new changes into your sandbox environment from downstream (e.g. production), over time some of those changes will inevitably fail to deploy into the sandbox due to the other discrepancies (a normal and supported occurrence in OrgFlow, in itself).
Such discrepancies that accumulate over time can lead to growing challenges in keeping the sandbox environment up to date. They can also be a source of merge conflicts, and they can make downstream deployments (for example deployments to production) either complete with a higher percentage of failed component or, in the worst case, fail due to failing Apex tests.
Sandbox environment recommendations
For the reasons outlined above, we strongly recommend that you keep sandbox environments as small and short-lived as possible by considering the following practices:
- Don't create a sandbox until it is actually needed
- Keep the scope of changes for a sandbox as small as possible, but no smaller
- Keep inextricably linked changes together
- Keep unrelated changes apart
- If two changes might need to flow downstream at different times, always do them in two separate sandboxes
- If development needs to be paused for a longer time, consider deleting the sandbox (while keeping the Git branch) and recreating a fresh sandbox from the Git branch later when development can resume
- When a sandbox has been merged downstream and deployed, delete it
- For staging and testing sandboxes, consider creating new ones for each release cycle
Salesforce org settings
Sign-in values
Sign-in values for connecting to an environment's Salesforce org can usually be inferred automatically from the base sign-in values stored in the stack, but you can also configure sign-in values directly on an individual environment, which will then override any inferred values.
See authenticating to Salesforce for more information.
API version selection mode
You can also specify settings on an environment to control how OrgFlow selects with API version to use when connecting to the org.
By default, these settings are not set on the environment, which means they will be inferred from the settings configured on the stack. This is recommended as it makes administration easier to manage API version settings for all environments in a single place.
However, there are scenarios where you might like specific environments to use a different API version selection mode than the rest of the stack, such as during Salesforce preview windows.
See the section about managing API versions to learn more.
Tags
Tags are arbitrary name-value pairs that you can add to environments. They are completely optional, but can be useful for a variety of purposes, such as:
- To help keep environments organized
- To add arbitrary information to environments that is useful to you
- To use for enviroment selection in schedules to make them more flexible
- To help keep hard-coded environment identifiers out of scripts and CI/CD pipelines
- To help avoid unnecessary commits and churn on your scripts and CI/CD pipelines
Tags are a simple but powerful automation feature of OrgFlow. They allow you to build schedules, scripts, CI/CD pipelines and other forms of automation that treat environments differently without having to hard-code environment identifiers into your scripts. Instead, you can set different tags on different environments and base your script logic on those tags.
Tags can either have no value (value-less tags) or any text value (value tags). Value-less tags are designed for purposes where there mere presense of the tag is sufficient, such as when representing and acting on boolean conditions (for example IsDisabled to indicate that an environment is temporarily disabled). Value tags are useful when you need to filter or carry out actions based on values that may differ between environments, such as send an email to the owner of an environment (for example OwnerEmail:dimitrius@acme.com).
Neither tag names nor tag values carry any special meaning to OrgFlow; you decide what names and values make sense to you, what they mean and and what to use them for. Both tag names and tag values are case-insensitive. Tag names may only contain alphanumeric characters, hyphens and underscores. Tag values may contain anything except newline characters.
Some examples:
| Tag | Value | Description |
|---|---|---|
Team | Engagement | Indicate which team has primary ownership of the environment. |
Release | Aug 2025 | Indicate which release the feature is slated for. |
IsInactive | Indicate that the environment should not receive upstream changes for the moment. | |
IsDeployed | Indicate that the environment has been merged and deployed to production, and is a candidate for cleanup. | |
Channel | #campaigns | Indicate the name of a Slack channel where the feature can be discussed. |
In the above examples, IsInactive and IsDeployed are value-less tags. They are named as boolean conditions in this example (starting with the word "is") but they don't have to be; naming is completely up to you.
Use cases
The potential use cases for tags are virtually unlimited and depend on your requirements, but here are some examples of what environment tags might be used for:
Categorize and group your environments and create schedules, scripts or CI/CD pipelines that apply particular logic or processing only for environments in a certain category or group. As an example, you might categorize all your environments as either
dev,test,staging. You might then create a schedule that flows in changes to Git every night, but only for environments with the tagCategory:dev, because no changes made intestandstagingenvironments should be preserved.Save arbitrary values on your environments and use those values as per-environment inputs to the logic or processing in your scripts or pipelines. As an example, you might designate a code owner for each development environment, and store the owner's email address on each environment with tags similar to
OwnerEmail:name@domain.com. In your CI/CD pipelines, you might then send an email to the owner of any environment where merge conflicts are detected.Flag your environments based on boolean semantics and use conditional logic or processing in your scripts or pipelines based on those flags. As an example, you might add a
noMergeFromDownstreamtag to some environments to allow environments to temporarily stop receiving automatic merges from downstream environments. In your schedule, you would then exclude any environments with this tag from processing.Link your environments to external resources. When adding a tag you can use a fully qualified URL as the tag value, OrgFlow renders the tag value as a clickable link in the web app. As an example, you might link each environment to a user story in a work item tracking system with tags similar to
Story:https://acme.visualstudio.com/workitems/2164. This can be useful for associating an environment with some external item in another system, for example a user story in a work tracking system, or a dedicated Slack channel where the environment's development efforts are discussed.
Locks
Whenever an operation runs in OrgFlow that might mutate the state of an environment (including files in its Git branch and metadata in its Salesforce org) OrgFlow puts a lock on the environment to ensure that it cannot be mutated by multiple operations running concurrently. Without this protection, an environment could end up in an inconsistent or corrupted state.
An environment's lock status can be seen on the environments page in the web app:

If an environment is already locked, and you start a new job that needs to lock the same environment, the new job waits up to 45 minutes for the existing lock to be released before failing.
Operations requiring locks
The following table shows some example operations and their resulting locks (this list is not exhaustive):
| Operation | Locks | Why |
|---|---|---|
| Create environment A | A | Creates branch, creates+mutates org |
| Flow in environment A | A | Mutates branch |
| Flow out environment A | A | Mutates org |
| Flow in environment A — check-only | - | No mutation |
| Flow out environment A — check-only | - | No mutation |
| Flow merge A to B | A + B | Mutates both branches and target org |
| Flow merge A to B — no source in | B | Mutates target branch and org |
| Flow merge A to B — git-only | B | Mutates target branch |
| Flow merge A to B — check-only | - | No mutation |
| Delete environment A | A | Deletes branch and/or org |
Manually unlocking an environment
In rare cases it may happen that an environment is left in a locked state by a job that terminated abruptly. This can happen if a managed worker gets terminated by cloud infrastructure due to maintenance or outages, or if you run an operation using the CLI and forcibly terminate the orgflow process.
An environment being left in a permanent locked state prevents any further operations against that environment until the situation is resolved.
In such cases the environment can be manually unlocked, either on the environment settings page in the web app, or using the env:unlock command in the OrgFlow CLI.