Stacks
A stack in OrgFlow essentially serves two purposes:
- It represents a bridge between your Salesforce production org and your Git repository.
- It represents a container for a set of related Salesforce environments between which you'd like to flow metadata changes.
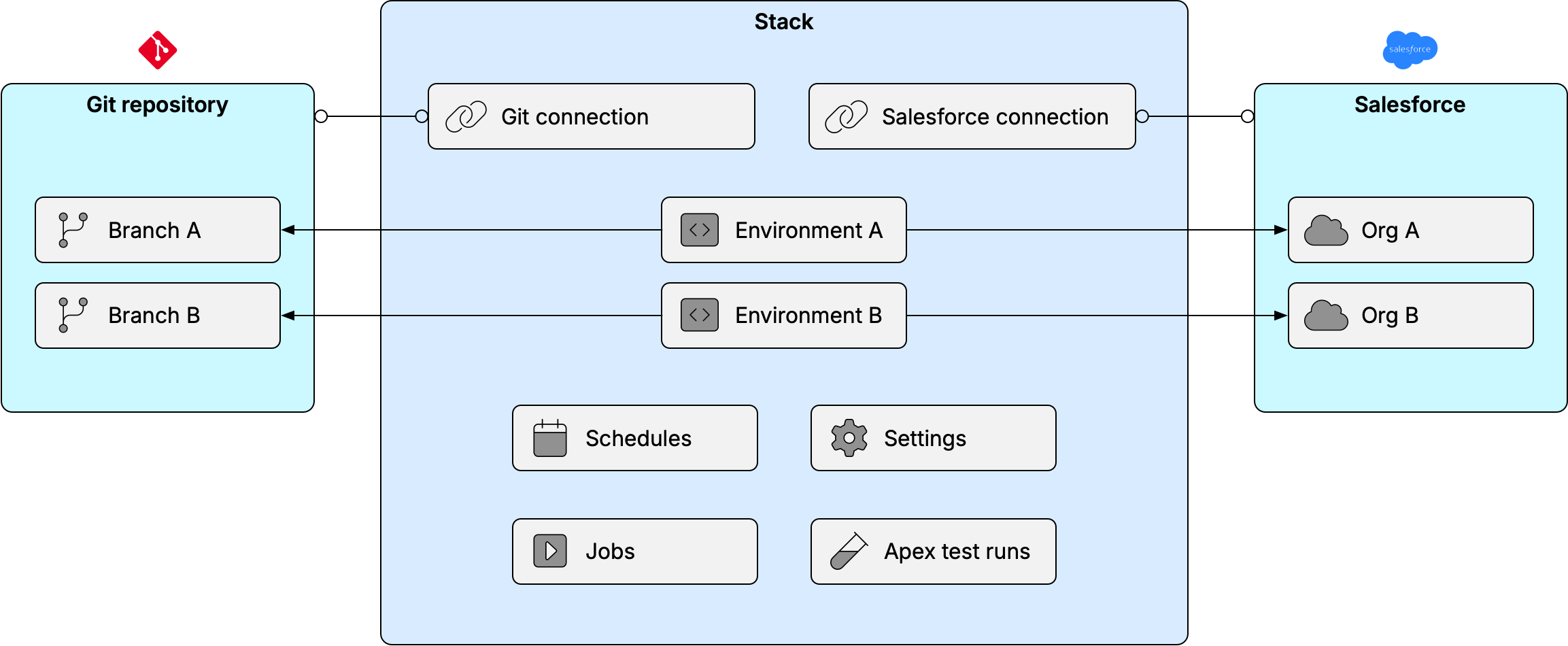
A stack contains:
- Settings for connecting to a Git repository
- Settings for connecting to a Salesforce production org
- One or more environments (including your production environment and any sandbox environments)
- Settings for which and how metadata should be stored, processed and flowed between environments
- Settings for selecting which API version to use when connecting to Salesforce
- History of jobs, test runs and schedules
At least one stack is needed to do any meaningful work in OrgFlow. In most cases you will only need a single stack, but you can also have several stacks in your workspace, for different purposes.
Git connection
The stack's Git connection tells OrgFlow how to connect and authenticate to your Git repository. The Git repository is used by OrgFlow for version control of your Salesforce metadata and for moving metadata changes between environments. For more information see understanding metadata version control.
Choosing a Git provider
OrgFlow does not include a Git repository - you must provide one yourself. Although the Git repository is utilized by OrgFlow for the purposes mentioned above, it is owned and managed by you. OrgFlow supports any standard Git repository, including those from popular commercial Git providers such as GitHub, Azure Repos, GitLab, BitBucket and others.
If you have advanced security or compliance needs, you can also use a self-hosted Git server as long as it's accessible from the public Internet and supports standard username/password authentication. For more information see authenticating to Git and self-hosting.
Providing connection details
When configuring the Git connection you provide the following information:
- Repository HTTP URL
- This is often shown in relation to a "clone" action
- Most providers offer a choice between HTTP and SSH protocols; OrgFlow supports only HTTP, so choose the corresponding URL
- Username
- Password or access token
How you obtain these values depends on your Git provider. Most commercial Git providers do not support authenticating from external tools using an actual username and password, but instead require the use of a personal access token. Separate steps are usually required to create such a token.
See authenticating to Git for more information.
Salesforce connection
The stack's Salesforce connection tells OrgFlow how to connect and authenticate to your production Salesforce org, in order to do things like manage sandboxes, retrieve and deploy metadata changes, and run Apex tests.
Sign-in values
When configuring the Salesforce connection you provide the following sign-in values:
- Username
- Optionally:
- Custom sign-in URL
- Password
- Security token (depending on your Salesforce security settings)
See authenticating to Salesforce for more information.
Environments
As mentioned above, a stack is a group of related environments. Each environment consists of a Salesforce org (production or sandbox) and a backing Git branch. You can learn more in our dedicated topic about environments.
All the environments in the same stack have several things in common:
Environments in a stack belong to the same Salesforce production org. A stack maps one-to-one with a production org, and can only contain that production org and sandboxes belonging to that production org. Sandboxes belonging to other production orgs do not belong in the same stack.
Environments in a stack share the same Git repository. Each environment in a stack is backed by a branch in that repository. Your production environment is typically backed by the
mainormasterbranch, while sandbox environments are backed by feature branches with names that you decide.Environments in a stack share a single metadata "code base" and will contain temporarily diverging but ultimately converging versions of that single code base. While development work is on-going, the environments in a stack will have differences, but there is an expectation that those differences will ultimately be reconciled as branches are merged and integrated changes are deployed to downstream environments. This aligns naturally with sandboxes sharing the same production org and branches in the same Git repository.
Environments in a stack can have metadata changes flowed between them. In OrgFlow, metadata changes are always flowed from one environment to another by merging between branches in the Git repository. If you intend to flow changes between any two environments, they must be in the same stack. (Though technically changes can of course also be ultimately propagated between different stacks through a shared production environment.)
Environments in a stack share a common configuration. You can customize which subset of metadata you want OrgFlow to track, keep in your Git repository and flow between the environments in the stack. You can also customize certain settings for how metadata is versioned and processed. All such settings are configured on a per-stack basis and are the same for all environments in the stack.
Environments which are not conceptually related in the ways described above do not belong in the same stack. As you can see there are several potential reasons why you might need more than one stack to support your Salesforce DevOps needs.
A stack is unstructured
It's important to understand that, while the environments in a stack are all related, they do not form an inherent structure within the stack. All environments in a stack are equivalent, and you can flow changes between any two environments as you see fit. There is no concept of downstream or upstream relationships between any particular environments, and no constraints forcing users to propagate or promote changes in any particular stages. The word "stack" itself refers to the concept of an unstructured collection of environments (usually visualized in OrgFlow as a vertical list resembling a stack of boxes).
See flowing changes for more information about how changes flow between the environments in a stack.
Metadata settings
Included metadata
A stack includes filtering rules for which subset of your Salesforce metadata that should be included in the flow. These filtering rules are stored in a file named .orgflowinclude in the root of the Git repository.
Metadata that matches the filtering rules is included in OrgFlow's automatic change detection, stored in your Git repository and flowed between the environments in your stack. Any metadata not matching the filtering rules is ignored by OrgFlow and will never be stored in your Git repository.
See the section about managing included metadata to learn more.
Version control settings
Additionally, a stack includes version control settings that you can use to customize how and where OrgFlow stores metadata in your repository. See the section on understanding metadata version control to learn more.
Salesforce API settings
A stack also includes settings that let you control how OrgFlow selects which API version to use when connecting to different Salesforce orgs in the stack.
This can affect the format and structure of the metadata retrieved from Salesforce and stored in different branches of your repository. It can also impact your ability to flow metadata between your environments, especially during Salesforce preview windows when some sandboxes may be on a preview version of Salesforce while other sandboxes (and your production org) are not.
These settings can also be overridden for individual environments.
See the section about managing API versions to learn more.
Using multiple stacks
The majority of teams support only a single production org with a single code base and a release pipeline. Such teams will normally only need a single stack in their workspace. However, some example scenarios where your team might need more than one stack include:
Supporting more than one production org. If your company owns multiple production Salesforce orgs (perhaps for different departments or as a result of M&A) you can use multiple stacks to support them. (But remember to ensure that you comply with the terms of your OrgFlow license, which normally stipulate that you can use a single license only to support a single business.)
Separating different DevOps needs. For example, you might use one stack to drive your change management and release pipeline. This stack would contain your production environment as well as all your development sandbox environments, and might only include a subset of your org's metadata. In addition you might have another stack, backed by different Git repository, to schedule regular commits of your production metadata to Git. This stack might contain only your production environment, but include all metadata, even types that you don't normally flow between environments such as dashboards and reports.