Flow in (retrieving from Salesforce)
A core feature of OrgFlow is the ability to detect new metadata changes in a Salesforce org, retrieve those changes and commit them to a Git repository. We call this process flow in or sometimes inbound flow. Together, flow in and flow out are key operations that help keep a Salesforce org in sync with a Git branch.
This diagram outlines the overall steps of the flow in process:
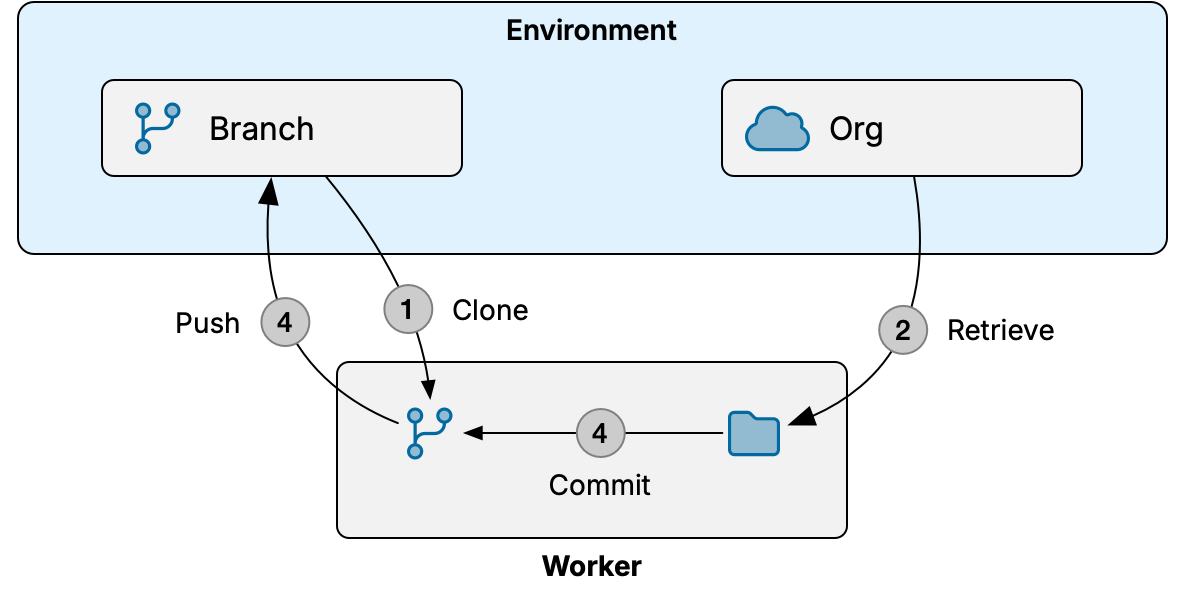
- Worker makes a temporary local clone of repository with environment's Git branch
- Worker retrieves metadata from environment's Salesforce org to a temporary local folder
- Worker commits metadata changes to local Git branch
- Worker pushes new commits to environment's remote Git branch (unless check-only mode was selected)
"Worker" in this context can be either a managed worker in OrgFlow's cloud, or the CLI running on your infrastructure.
Starting a flow in job
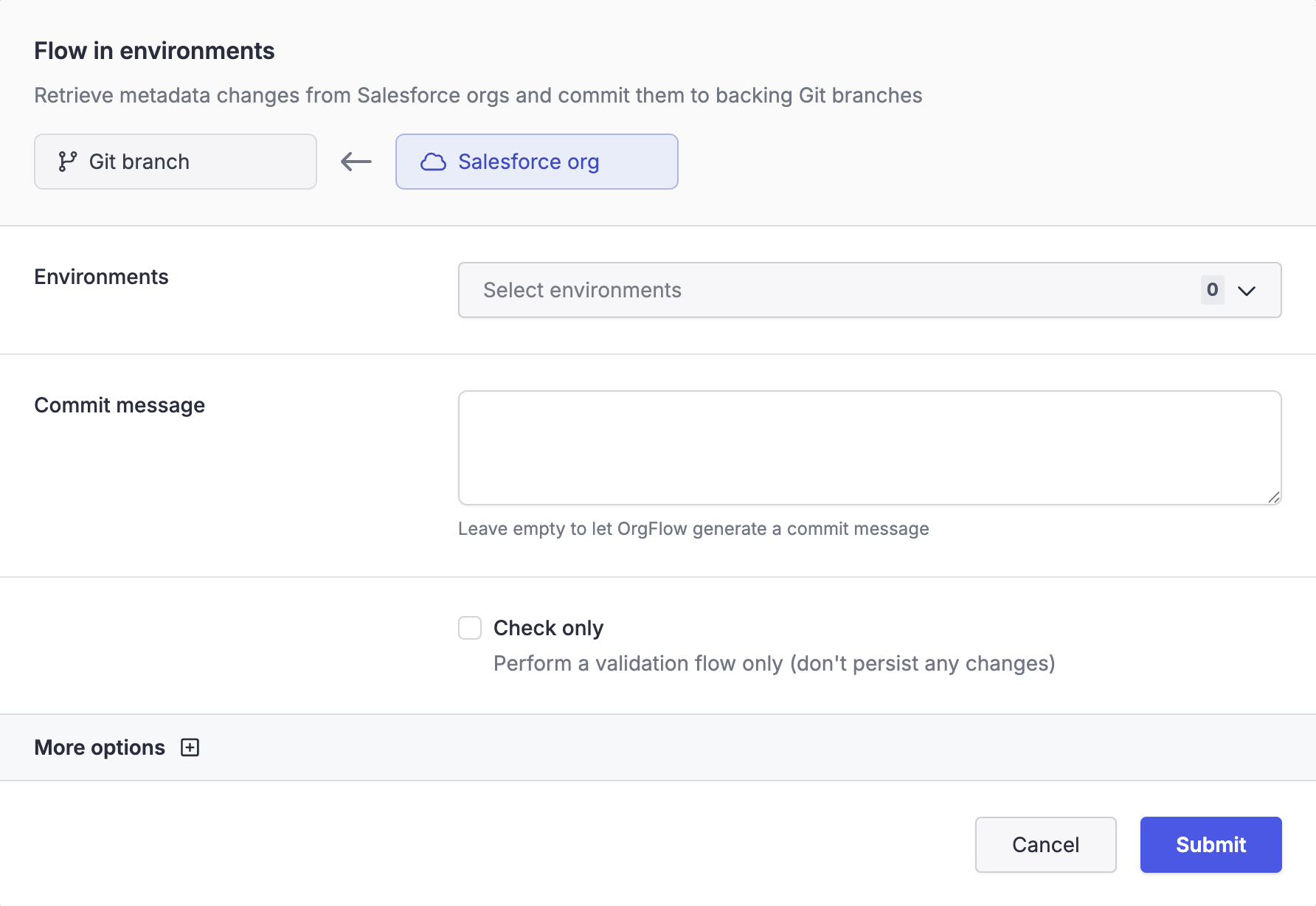
To start a flow in job using the OrgFlow web app, navigate to the environments page, open the flow dropdown menu and select the flow in menu item. This opens the flow in dialog where you configure the inputs and options of the flow in job:
OrgFlow CLI
To start a flow in job using the OrgFlow CLI, use the env:flowin command.
Many of the available options in the flow in dialog are self-explanatory. The following sections describe some options in more detail.
Check only
This option runs the flow in job in check-only mode. In this mode, the environment's state in OrgFlow's cloud remains unchanged and the committed changes are never pushed to the remote repository. The result is a dry run that does not impact the state of the environment or Git repository in any way, but still allows you to discover potential errors and inspect the job result.
Retrieve mode
There are two retrieve modes: full and partial. By default, OrgFlow will automatically select which mode to use, using partial when possible and safe but falling back to full when necessary.
Full
Full retrieve involves retrieving all of the metadata that is included by the include specs and relying on Git to determine what's changed since the last flow in.
At a high level, the process looks like this:
- OrgFlow determines the metadata types that are included by the include specs
- OrgFlow asks Salesforce for a list of all the metadata items of those types
- All of the metadata items that match the include specs are retrieved from Salesforce
This is the most thorough and well supported retrieval mode because it doesn't require source tracking, but it can be substantially slower than a partial retrieve due to the potentially large volume of metadata that is retrieved.
Partial (source tracking)
Partial retrieves utilize Salesforce's source tracking functionality to identify which metadata items have changed since the last flow in, and retrieves only the metadata that's changed.
At a high level, the process looks like this:
- OrgFlow maintains a baseline source tracking version number for each source tracked environment
- OrgFlow asks Salesforce for all the source tracking records since the baseline version
- Those source tracking records are filtered to include only the metadata items that are included by the include specs
- Those metadata items are retrieved from Salesforce using the metadata API
This is the fastest retrieve mode because it typically results in only a small subset of metadata needing to be retrieved, greatly reducing the time it takes for the retrieve to complete. However, there are some limitations and known issues with source tracking.
Collect retrieved metadata archives
This options saves the "raw" retrieved metadata archives as artifacts on the job, exactly as they were sent back from the metadata API before any processing was applied by OrgFlow. This can be helpful when diagnosing issues with inbound flow, for example to understand whether metadata in your repository looks a certain way because of OrgFlow's processing, or because Salesforce simply provided it in that way.
One artifact is created per retrieved batch.
Merge conflicts
The flow in process uses merging of changes to safely commit incoming metadata changes from the environment's Salesforce org while preserving any undeployed changes in the Git branch.
When the same component has changed both in the Git branch and in the Salesforce org, it is possible for merge conflicts to occur during flow in. The merge conflicts option lets you control how OrgFlow should behave when merge conflicts are detected. The use semantic merge option enables metadata-aware merge logic to help avoid some types of merge conflicts.
See merge conflicts for more information about these options.
Force
Force mode resets the metadata in the Git repository to match the state of the metadata in the Salesforce org.
It does this by bypassing the branching strategies used to support merging changes. The retrieved metadata is applied to and committed onto the head of the environment's branch. Author attribution is still supported in force mode.
Be careful with undeployable components
Force mode will reset everything in the Git branch to match the state of the Salesforce org. This means that undeployable components will also be reset.
Undeployable components will almost certainly be ahead in the Git repository, compared to the Salesforce org. Resetting these components to match the org versions will revert these changes.
Partial retrieve limitations
Partial retrieve is not always possible, and there are some known issues with source tracking that sometimes prevents metadata changes from being reliably detected in a Salesforce org.
For a partial retrieve to be possible, all of the following criteria must be met:
- Source tracking must be enabled in the Salesforce org
- OrgFlow must have previously done a full retrieve of the environment in order to establish a baseline
- The include specs must not have changed since the last flow in
- Force mode must not be selected
- The environment must have been flowed in in the past 30 days
- There must not have been an external deployment since the last flow in of the environment
An external deployment is a deployment that has been done with a tool other than OrgFlow, for example using changesets. External deployments may not update source tracking records for the metadata items that they touch, so OrgFlow cannot be confident that the source tracking history is complete if there has been an external deployment since the last flow in.
Support for non-source tracked types
Some metadata types do not support source tracking; OrgFlow is still able to support these types during a partial retrieve.
It does this by effectively doing a full retrieve of the types that are not supported by source tracking.
The types that do not support source tracking varies with each Salesforce API version and can be seen in Salesforce's metadata coverage report. Because these types vary between Salesforce API versions, the types affected in each environment will be impacted by the API version selection mode that you have chosen for the environment.
Known issues with source tracking
OrgFlow's partial retrieve functionality is powered by Salesforce's source tracking functionality, and it is only as good as Salesforce's ability to accurately maintain these source tracking records.
Unfortunately there are some known issues with Salesforce that result in some changes not being reflected in Salesforce's source tracking. One example of this is deleting a custom field from a custom object. In this case, Salesforce should create a source tracking record to indicate that the field is deleted, but instead it simply does not create the record. If you encounter this issue, you should raise a case with Salesforce as we are not in a position do anything about it.
This same issue will impact any tool that uses source tracking, including the Salesforce CLI.
For this reason we suggest that you run flow in with full retrieve enabled from time to time in order to catch any changes that source tracking may have missed.
Automatic change detection
OrgFlow is capable of automatically detecting metadata changes in the environment's Salesforce org. This is achieved using a combination of two methods:
- In case of partial retrieve, OrgFlow queries the Salesforce org for new changes since the last flow in, to minimize the retrieve size
- After retrieving metadata from the org, OrgFlow compares it to the metadata in the Git repository (at the correct point in time), and identifies components that have changed
This approach works regardless of retrieve mode, which means that you no longer need to worry about remembering which components need to be added to a deployment — even for orgs that do not have source tracking enabled (such as a production org).
Merging changes
Part of the magic of OrgFlow is its ability to merge changes in a Git repository with the changes in a Salesforce org, without one side overwriting the other.
For example, if the help text of a custom field has been changed in Git, and someone else changes the description of the same field in the org, the flow in process will merge those two changes together, and neither change will be overwritten by the other. This is one of the fundamental pieces that enable OrgFlow to merge changes between environments without clobbering changes in one org with the changes from another org.
See understanding metadata version control for more in-depth information on how OrgFlow utilizes Git to achieve this and other benefits.
To enable this, OrgFlow maintains some state information about each included metadata item in an environment. The state information is stored in OrgFlow's cloud. Part of this state information includes commit hashes that OrgFlow can use to compare the current state of the metadata item in the Git repository to the state of the metadata item in the Salesforce org. This is what enables automatic change detection, and also allows the Git repository to be ahead of the Salesforce org without risking data loss during a flow in.
What's stored in OrgFlow's cloud?
The state information that is stored in OrgFlow's cloud does not include the metadata items themselves, but it does include the names and types of the metadata items, commit hashes, and source tracking version numbers.
Merging of changes can be bypassed by enabling force mode for the flow in job.
Batching
Regardless of retrieve mode, OrgFlow will usually split the metadata to be retrieved into smaller batches and retrieve several batches concurrently. This has two main benefits:
- It's usually quicker to retrieve several smaller metadata archives from the metadata API in parallel, than it is to retrieve a single larger one
- The metadata API imposes limits on the number of items and the total overall download size per retrieve, and splitting the retrieve into smaller batches allows OrgFlow to circumvent those limits.
When deciding how to split the metadata to be retrieved into batches, OrgFlow must take into account several factors. Firstly, OrgFlow will determine an optimal batch size and from that the number of batches to retrieve. Then, OrgFlow must identify metadata items that need to be retrieved in the same batch. This is a crucial step because Salesforce's metadata API can return inconsistent results for some metadata types if those types take dependencies on other types or items that are not included in the same batch.
The result of these batching requirements is that you may see some retrieve batches that are larger or smaller than others during a retrieve. This is normal behavior and is to be expected.
There are cases where only a single batch will be retrieved:
- The number of metadata items to be retrieved is very small and creating more than one batch would be inefficient
- All of the metadata items to be retrieved must be retrieved in the same batch because of the limitations in the metadata API
Author attribution
When committing metadata to Git, OrgFlow attempts to identify the Salesforce user who last changed each metadata item that is to be committed. A combination of source tracking data (when available) and the last modified by property on the metadata item is used to determine this.
OrgFlow will then commit changes by each author separately, assigning the identified Salesforce user as the author of each commit. The Name and Email fields from the User object in Salesforce are used to create the Git author string (i.e. user.Name <user.Email>).
Author attribution helps to build up a rich history in Git, recording a name on each change made to your Salesforce metadata.
Attributing multiple changes
Author attribution is only able to record a single author per component and flow in. If two users have changed the same metadata item since the last flow in, then both changes will be attributed to the user who made their change last. To avoid "skipped" changes is Git history, flow in environments frequently.
Occasionally it won't be possible to attribute an author to a change (for example when a metadata item has been deleted and source tracking is not available for the org). In these cases the author will default to Unknown Author <unknownauthor@orgflow.io>.