Flow out (deploying to Salesforce)
A core feature of OrgFlow is the ability to determine new metadata changes in a Git repository and deploy those changes into a Salesforce org. We call this process flow out or sometimes outbound flow. Together, flow out and flow in are key processes that help keep a Salesforce org in sync with a Git branch.
This diagram outlines the overall steps of the flow out process:
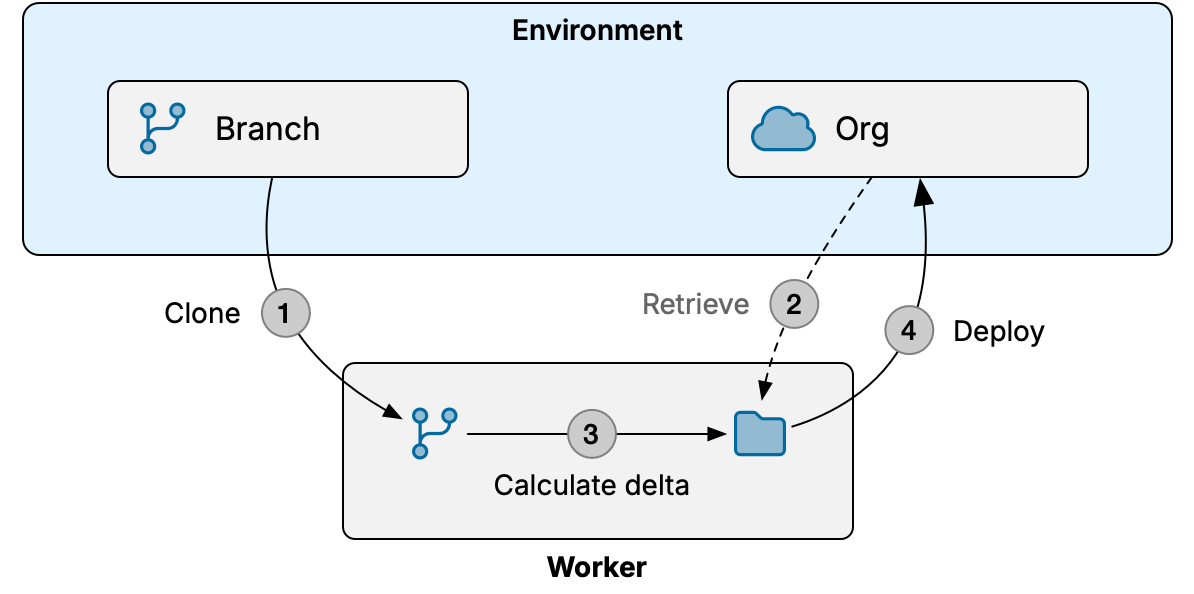
- Worker makes a temporary local clone of repository with environment's Git branch
- If org comparison is used, worker retrieves metadata from environment's Salesforce org for comparison
- Worker determines changes in the local Git branch since last flow out and creates a delta archive
- Worker deploys delta archive to environment's Salesforce org (or validates if check-only mode was selected)
- If any components failed, worker repeats steps 3 and 4 while excluding failed components
"Worker" in this context can be either a managed worker in OrgFlow's cloud, or the CLI running on your infrastructure.
Starting a flow out job
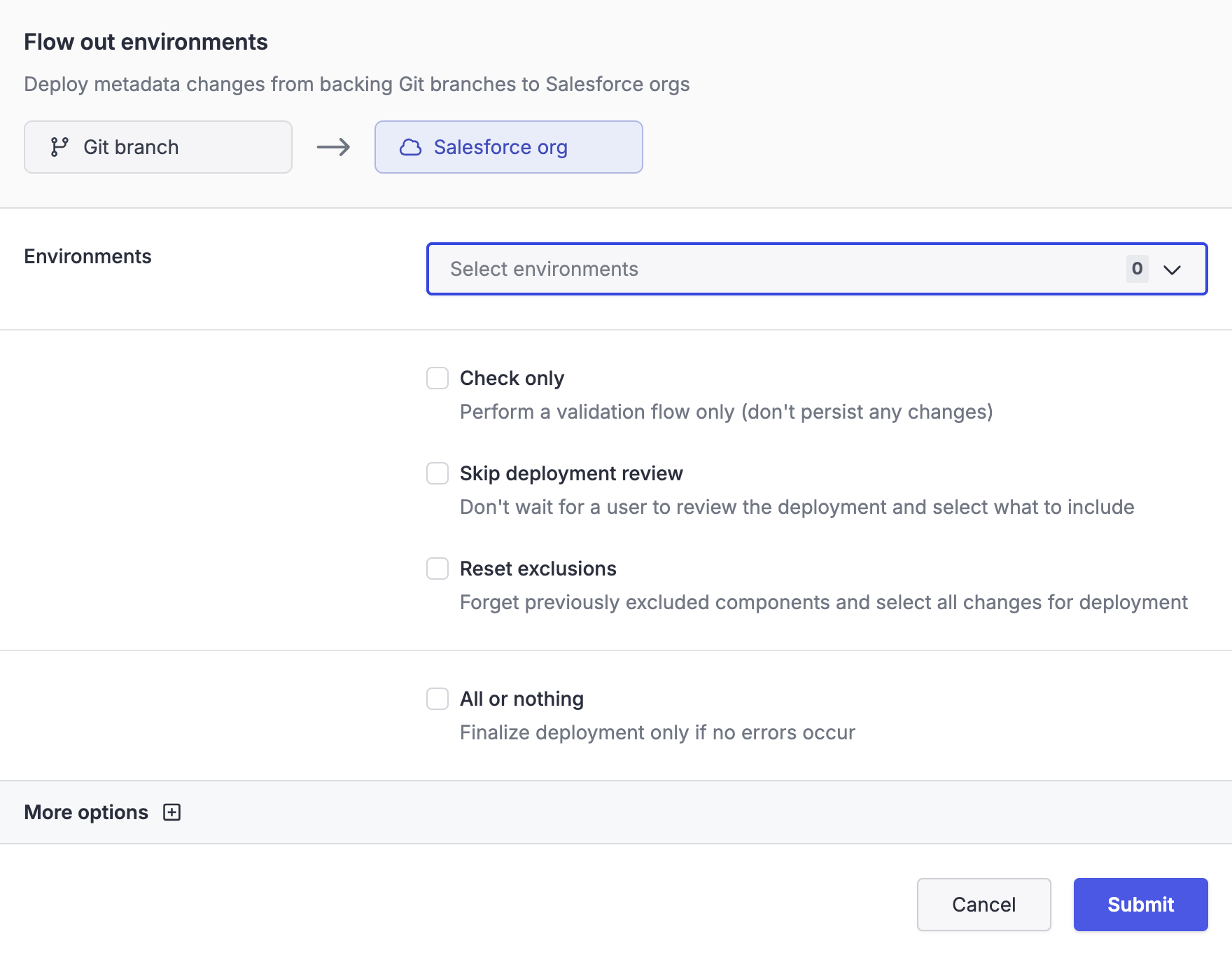
To start a flow out job using the OrgFlow web app, navigate to the environments page, open the flow dropdown menu and select the flow out menu item. This opens the flow out dialog where you configure the inputs and options of the flow out job:
OrgFlow CLI
To start a flow out job using the OrgFlow CLI, use the env:flowout command.
Many of the available options in the flow out dialog are self-explanatory. The following sections describe some options in more detail.
Check only
This options runs the flow out job in check-only mode. In this mode, the environment's state in OrgFlow's cloud remains unchanged and the deployments to Salesforce run as validation deployments (i.e. Salesforce will validate the deployment but not actually apply the changes to the metadata in the org). The result is a dry run that doesn't impact the state of the environment or Salesforce org in any way, but still allows you to discover potential errors and inspect the job result.
Skip deployment review
By default OrgFlow will pause before the first deployment attempt and wait for a user to review the detected differences, select what to include in the deployment and confirm to proceed. This option skips this review step and automatically proceeds with the deployment.
Any exclusions (components not selected for deployment) that were in effect during the last succesful flow out will be retained, unless you also enable the reset exclusions option.
Reset exclusions
When a user makes an active choice to exclude one or more metadata components from an outbound flow, this choice is remembered for subsequent outbound flows. Enabling this option clears this memory for the current environment, and reverts back to including all detected changes in the outbound flow. If you also enable the check only option, exclusions are reset for the current outbound flow but not persisted.
All or nothing
Partial success can be disabled by enabling all or nothing mode. In this mode, OrgFlow attempts the first deployment like normal. However, if some components fail to deploy during the first attempt, the flow out process will switch to using check-only mode for the remainder of the deployment attempts.
The result is that either all metadata changes are successfully deployed, or none of them are deployed and the org remains unchanged. Because OrgFlow continues to complete all the deployment attempts (now having switched to using check-only mode for the remaining attempts) you still get the full list of deployment failures across all the attempts.
Diff mode
OrgFlow automatically determines which metadata changes in an environment's Git branch are not yet in its Salesforce org. This means you don't need to worry about remembering which components need to be included in a deployment.
The diff mode option lets you control which change detection mechanism OrgFlow should use for the flow out. There are two modes: history diff and org comparison. These two modes can produce slightly different results, so it's important to understand the difference between them.
History diff
History diff is quicker than org comparison, but there are some caveats to be aware of.
This mechanism involves checking the Git history of each metadata item to identify those that have changed in the Git branch since OrgFlow knew they were last equal to the Salesforce org. It does not take into account changes made in the Salesforce org since then - only changes in the Git branch are considered. Because of this, deployments using history diff tend to be smaller, and take less time to calculate and deploy.
If a component has changed only in the Salesforce org, it will not be identified as a difference by history diff.
However, if a component has changed in the Git branch and the Salesforce org, the changes made in the Salesforce org may be overwritten by the changes in the Git branch. Clobber detection can identify such components and warn you about potential clobber, but only if the Salesforce org has source tracking enabled. To ensure no changes in the org are clobbered by the deployment, you should first flow in the environment to merge any changes in the Salesforce org into the Git branch, and then flow out immediately after.
You should use this option by default if you don't mind that some of the included metadata in the Salesforce org might be ahead of the metatdata in the Git branch.
Org comparison
Org comparison is more thorough and accurate than history diff, but also slower.
This mechanism involves retrieving all the included metadata from the environment's Salesforce org, and comparing it to the metadata at the head of the Git branch. Any metadata items that differ between the retrieved items and the items at the head of the Git branch will be deployed. Because of this, any changes that are in the Salesforce org but not yet in the Git branch will be overwritten by the metadata that is being deployed. Clobber detection can identify such components and warn you about potential clobber, but only if the Salesforce org has source tracking enabled. To ensure no changes in the org are clobbered by the deployment, you should first flow in the environment to merge any changes in the Salesforce org into the Git branch, and then flow out immediately after.
You should use this option in scenarios where history diff would not be sufficient, such as after refreshing the environment's sandbox, or in any scenario where you want to ensure that all of the included metadata in the environment's Salesforce org match the metadata at the head of the Git branch.
Change detection results
The following table shows the resulting metadata in the environment's Salesforce org after a successful flow out, for all combinations of changes and change detection mechanisms:
| Changes | History diff | Org comparison |
|---|---|---|
| Component changed only in branch | Branch | Branch |
| Component changed only in org | Org | Branch |
| Component changed in both branch and org | Branch | Branch |
The following table shows the same if a flow in were run immediately before the flow out:
| Changes | History diff | Org comparison |
|---|---|---|
| Component changed only in branch | Branch | Branch |
| Component changed only in org | Org | Org |
| Component changed in both branch and org | Both (merged) | Both (merged) |
Purge on delete
The Salesforce metadata API has a purge on delete option for deployments. The flow out process also supports this option. Enabling purge on delete means that metadata items deleted by a deployment will bypass Salesforce's recycle bin and become immediately eligible for deletion in the org.
Apex test options
Clobber
For orgs that have source tracking enabled, OrgFlow is able to determine whether clobber would occur if the deployment were to continue. Clobbering in this context means deploying a metadata item into a Salesforce org that would overwrite pre-existing changes to that metadata item.
For example: If user A updates an Apex class in a sandbox to fix a bug, and user B deploys a version of the same Apex class that doesn't include the bug fix, then the bug fix will be removed (or "clobbered") by the deployment.
Clobber detection works by querying the Salesforce org for source tracking records since the environment was last flowed in. Those records are compared to the metadata about to be deployed, and if there is any overlap then the deployment is determined to cause clobber. Because this feature depends on source tracking, it is subject to the same restrictions as partial retrieve.
The clobber option lets you configure how OrgFlow should behave when clobber is detected. The default option is automatic which means OrgFlow will automatically proceed with the flow out if there is potential clobber, but abort the job before the deployment begins if certain clobber is detected. You can change this to either accept which means the flow out will proceed regardless, and abort which means OrgFlow will abort the job if either potential or certain clobber is detected.
Potential clobber means OrgFlow cannot reliably determine whether a particular component would be clobbered or not, either because source tracking is not enabled in the Salesforce org, or because the component's type is not supported by source tracking.
Max attempts
This options lets you configure how many deployment attempts OrgFlow makes to try and achieve a partially successful outcome, before giving up and marking the entire process as failed. This option defaults to 5 attempts, and it should normally not be necessary to increase it except for very problematic deployments, in which case you should consider whether a partial success with that many undeployed components is really desirable, or whether you should rather try to investigate and address the underlying reasons.
Collect deployment archive artifacts
This options saves the delta deployment metadata archives as artifacts on the job, exactly as they were uploaded to the metadata API by OrgFlow. This can be helpful when diagnosing issues with outbound flow, for example to understand the underlying reasons for deployment failures.
One artifact is created per deployment attempt.
Reviewing the deployment
Unless you've enabled the skip deployment review option, OrgFlow pauses before the first deployment attempt and prompts for a user to review and confirm the contents of the proposed deployment.
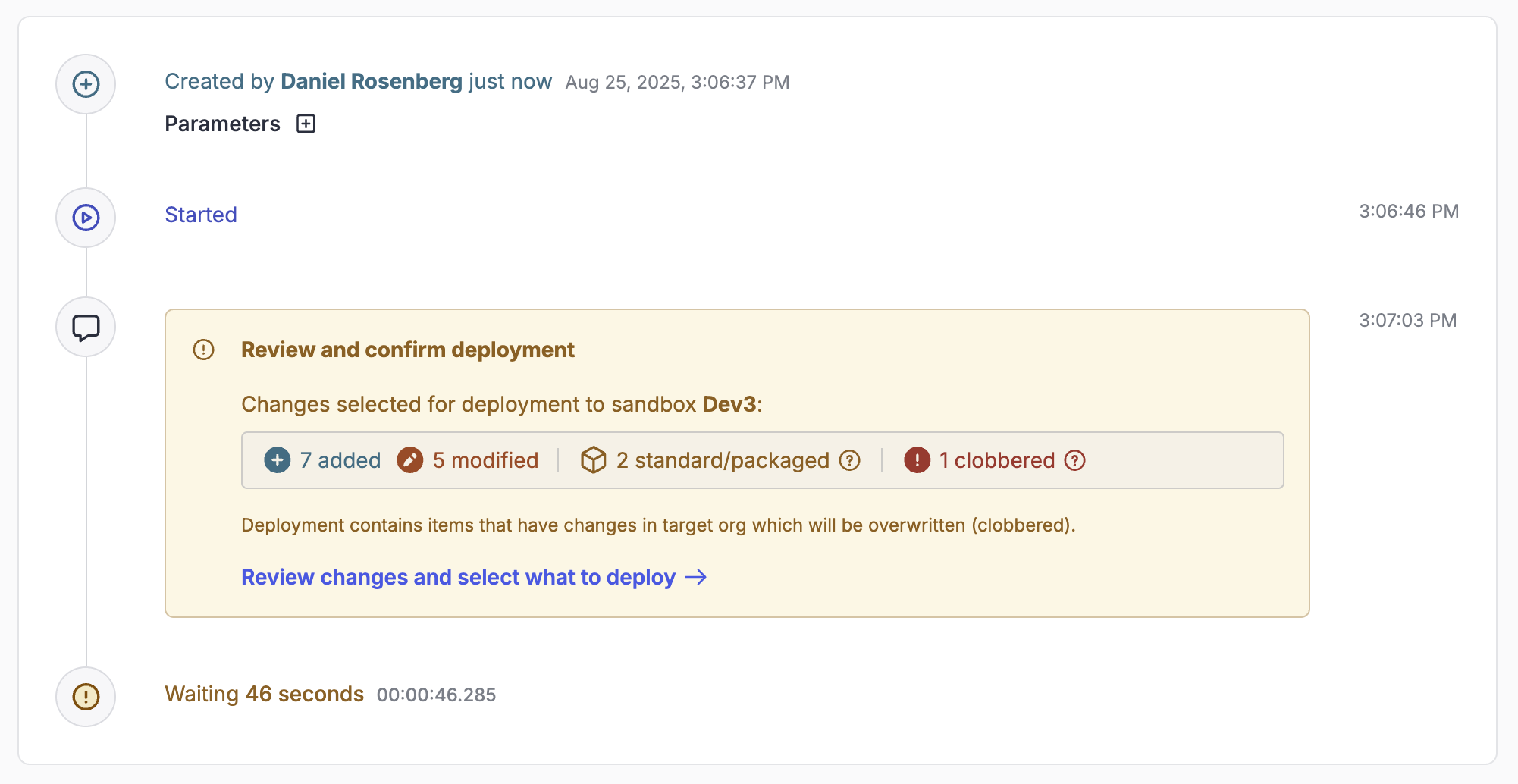
The Review and confirm deployment inquiry on the job timeline shows you the high-level counts of detected changes selected for deployment. Select Review changes and select what to deploy to see the deployment contents in more details.
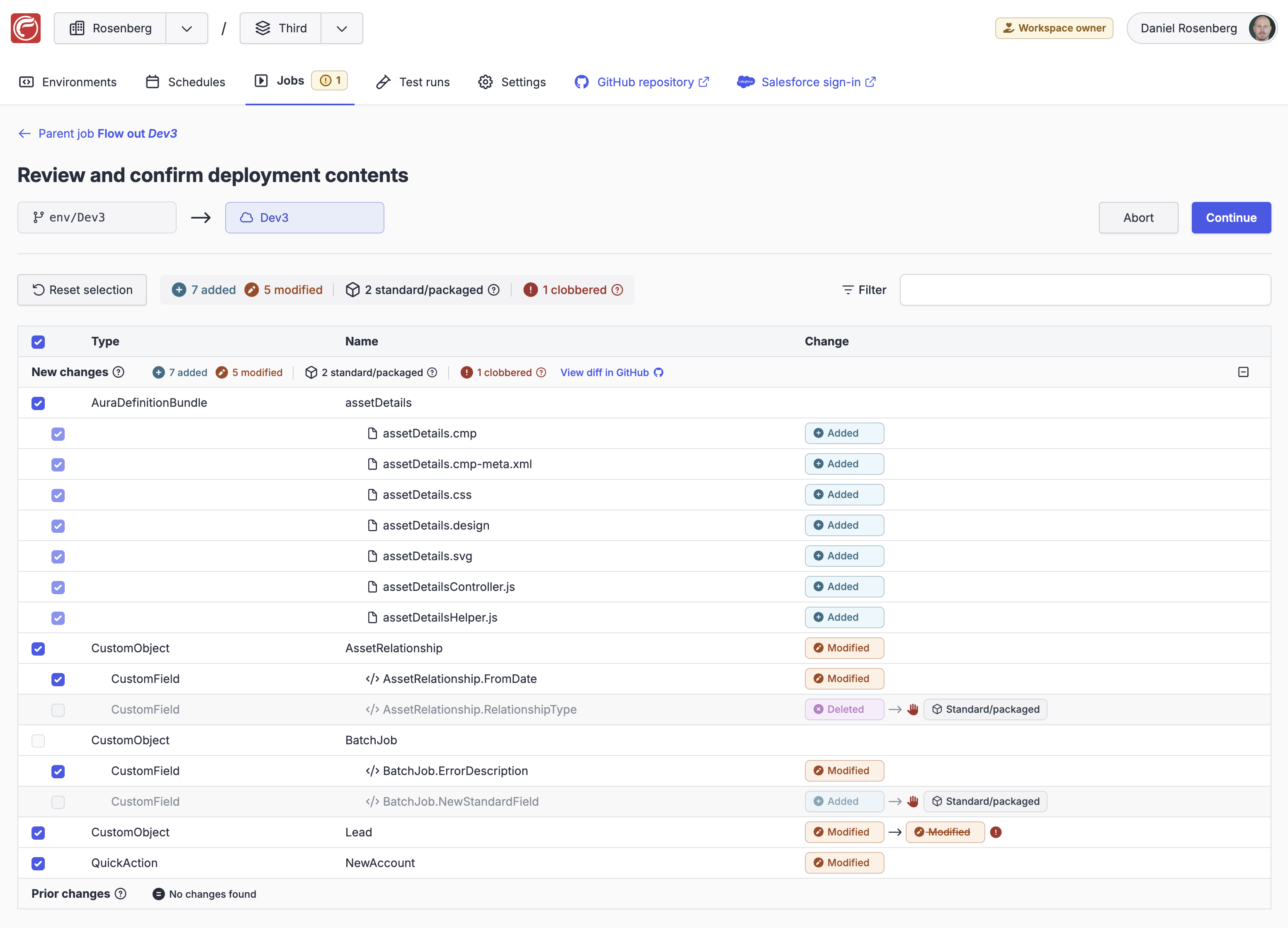
New vs. prior changes
If history diff is used, the changes are diveded into two sections:
- The new changes section contains new changes committed or merged to the environment's Git branch since the last successful outbound flow
- The prior changes section contains changes that were excluded or failed to deploy in the last successful outbound flow
This distinction can be very useful particularly during flow merge operations, because it helps you you focus on only the changes that are new to this outbound flow.
Selecting what to include
Each detected change has a corresponding checkbox that allows you to select whether to include that change in the deployment. Unless you've enabled the reset exclusions option, any components that were excluded in the previous outbound flow of this environment will default to unselected.
Selection is possible only on actual metadata components, not on mere content items. For example, you can select or deselect the Aura component shown in the example, but not the individual resource files because those are not components in their own right; selection/deselection automatically applies to all items belonging to the Aura component.
Deploying only a subset of changes can be useful in a variety of situations:
- Undesired changes were detected only after they were merged into the target environment
- Changes must be deployed in stages for business reasons
- Situations where some types of changes cannot be deployed simultaneously due to bugs or limitations in the Salesforce metadata API and deployment engine
- Certain "chicken-and-egg" problems where some components must first be deployed, so that some manual post-deployment step can then be performed, so that other components can finally be deployed successfully
- Permanently excluding failing components that will never succeed, in order to avoid unnecessary deployment attempts and failure indications
Unless you've enabled the check-only option, any exclusions you make here are remembered for subsequent outbound flows.
Standard/packaged metadata
Some types of detected metadata changes are always excluded from deployments and cannot be selected:
- Standard metadata components (built into the Salesforce platform) cannot be added or deleted by deployment. Instead you should ensure that enabled features, settings, licenses and permissions are consistent across the orgs in your stack.
- Packaged metadata components (installed by managed packages) also cannot be added or deleted by deployment. Installed packages and their versions should instead be kept in sync across the orgs in your stack.
In the example shown, the deleted custom field AssetRelationship.RelationshipType and the added custom field BatchJob.NewStandardField are both marked as standard/packaged and will be excluded from the deployment.
Clobbered changes
In situations where OrgFlow is able to reliably determine clobber, the review also includes information about changes in the target org that would be clobbered by changes in the deployment.
In the example shown, the custom object Lead has been modified in the target org, and that change would be clobbered (overwritten) by the modification to the same custom object in the proposed deployment, if this component were to be included in the deployment. Based on this information you might consider to avoid this clobber by either excluding this component from the deployment or aborting the outbound flow, and then running a flow in operation on the environment in order to merge the changes in the org with the changes in the branch, before running the outbound flow again.
Deploying metadata
Once OrgFlow has determined changes that are candidates for deployment, and a user has selected what changes to actually include in the deployment, the flow out process moves on to deploying them into the Salesforce org via the metadata API.
Partial success
When deploying metadata into a Salesforce, it's possible that some metadata items to fail to deploy, especially into sandbox environments. As your codebase grows, the likelihood of components failing to deploy grows too. Sometimes the components that fail to deploy are benign or don't impact the area of functionality that you are wanting to merge into a new environment.
Most Salesforce deployment tools would simply fail the deployment until all the errors have been fixed. OrgFlow however is capable of partial success, meaning that changes that can be deployed are not blocked by those that cannot.
The process looks like this:
- OrgFlow automatically identifies the components that need to be deployed
- OrgFlow attempts to deploy all of those components
- If any components fail, try again with the failed components excluded
- Repeat the above step until either the deployment succeeds, or OrgFlow can no longer retry the deployment
- If the deployment eventually succeeds, record any components that could not be deployed as undeployed components
There are a number of reasons why OrgFlow may reach a point where it can no longer make any further deployment attempts. Some examples include:
- Salesforce reports incorrect component names when they fail, preventing OrgFlow from excluding them from the next deployment attempt
- The maximum number of deployment attempts is reached
- Every changed component is undeployable, so there's nothing left to try to deploy
In most cases OrgFlow will be able to complete a partial deployment before any of the above conditions occur.
Eventual consistency
The purpose of partial success is to allow you to move changes between Salesforce orgs more easily, with a more forgiving deployment model. If a flow out succeeds partially, you can fix the issues that caused some components to fail, and then rerun the flow out. You can apply such fixes wherever is more practical: directly in the target environment's Git branch, in the Salesforce org, or even in a different OrgFlow environment followed by a new merge.
In the meantime, additional changes can continue to flow in every direction — even changes made in the Salesforce org to the undeployable components themselves. Once those components can be deployed, they are no longer classed as undeployable components and the Git branch moves closer to consistency with the Salesforce org.
This model can be throught of an application of the eventual consistency model in the context of Salesforce DevOps. For a deeper dive on this topic see our blog post Applying the Eventual Consistency Model to Salesforce DevOps.
Here's a simple example of eventual consistency in action:
Alice has been working on an Apex class in sandbox A. Her new Apex class references a custom field on Account called First_Contact_Date__c. Meanwhile, Bob has been cleaning up the production org and has deleted the First_Contact_Date__c custom field. Alice decides that she'd like to bring the latest production changes into her sandbox so she uses OrgFlow to merge from production into her sandbox environment. As part of the merge process, OrgFlow flows out the merged metadata. During the flow out, the First_Contact_Date__c field cannot be deleted from Alice's sandbox (because her Apex class depends on it), so OrgFlow excludes it from the deployment and completes a partially successful flow out of all the other changes that were merged in.
Now, First_Contact_Date__c is an undeployable component in Alice's sandbox environment. She inspects the deployment error and realises that she needs to update her Apex class to no longer reference the deleted field. She logs into the Sandbox and makes the required changes to her Apex class. On the next flow out, the First_Contact_Date__c will be deployed (deleted) because she's resolved the issue that was preventing this in the first place.
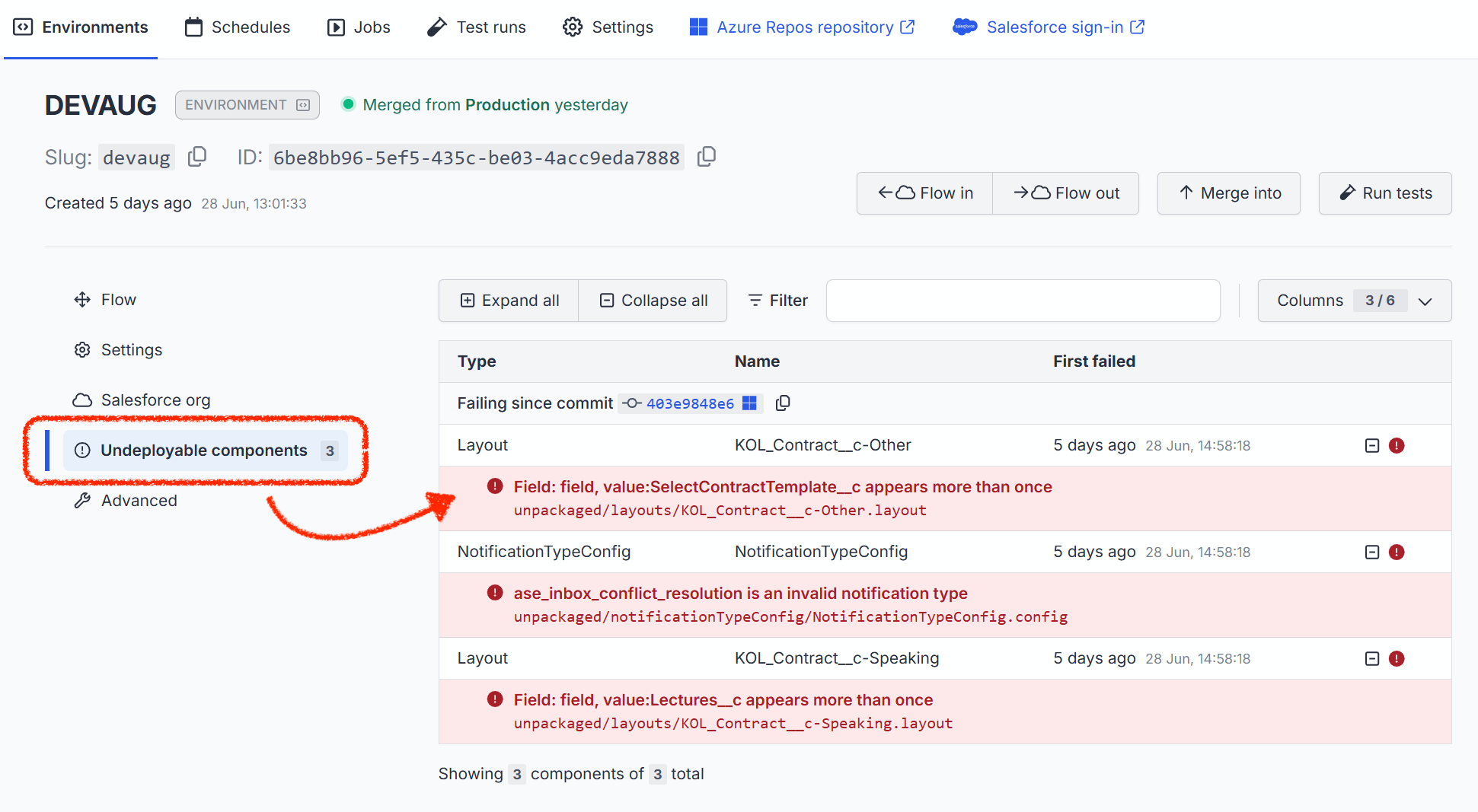
Undeployed components
Because you can optionally select what to include in deployment, some detected changes might be omitted from the flow out. Additionally, because of partial success, it's also possible for the flow out process to succeed even if some metadata items that were selected for deployment actually failed to deploy.
In this situation, OrgFlow will create an undeployed component record for each metadata item for which changes were found in the branch, but which was not deployed to the org. The undeployed component records help OrgFlow keep track of changes in the environment's Git branch which have yet to be deployed.
Undeployed component records are stored in OrgFlow's state store, and can be viewed in the web app. A count of the number of undeployed components is displayed on the Environments page (in yellow in the Git branch box of each environment):
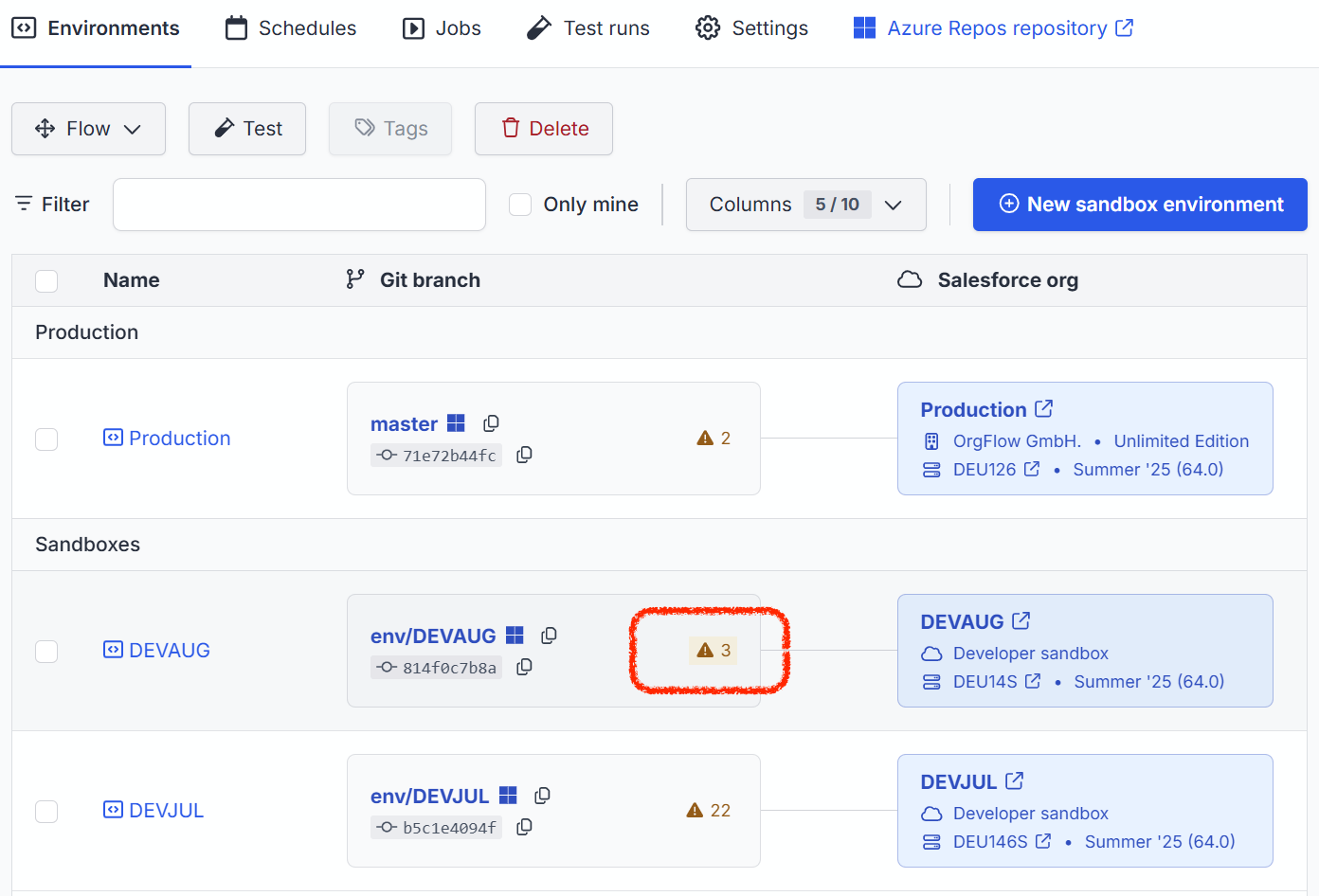
Clicking that count will take you to the Undeployed components tab of the environment details page: