Understanding metadata version control
You may have noticed that the name OrgFlow is often accompanied by the tagline "true Git-based DevOps for Salesforce". The term "Git-based" is not an exaggeration — version control (sometimes called source control) using a Git repository is at the very core of OrgFlow, and fundamental to the way it works.
Getting familiar with Git
OrgFlow uses the distributed version control system Git for all its version control operations. Git is by far the most widely adopted version control system in the world.
If you are not at least somewhat familiar with Git, you may find parts of OrgFlow challenging to understand. OrgFlow embraces Git and doesn't try to abstract away its concepts from you. Instead OrgFlow is transparent about how it uses Git, and exposes this information to you in Git terms so that you can remain in control and be more effective by also interacting directly with Git outside of OrgFlow.
We therefore recommend that, as you get familiar with OrgFlow, you also familiarize yourself with Git. Thanks to Git's wide-spread adoption and popularity, there is a wealth of resources available. A good place to start is the official Git documentation page which contains an entire book, reference manual, videos and plenty of links to other learning resources.
Benefits of Git
OrgFlow is fundamentally about flowing metadata changes between Salesforce orgs, and Git version control is at the center of this flow. Unlike in many other Salesforce deployment and DevOps tools, metadata changes are never copied directly between Salesforce orgs, but instead always flow through the branches of a connected Git repository.
Relying on Git for all flowing of changes is what enables many of OrgFlow's benefits.
Automatic change detection
Git fundamentally deals in changes — every commit is a delta, i.e. a set of changes across a set of files, compared to what those files looked like in the previous commit. This makes Git especially adept at detecting changes made in your Saleforce orgs, so that your team doesn't have to remember exactly which components they changed as part of a bigger development effort. Given a freshly retrieved copy of the metadata in a Salesforce org, Git can quickly figure out which lines of metadata are different compared to what's already in the repository.
Detailed version history
Git remembers every change forever. By regularly flowing changes from your Salesforce orgs into their Git branches, over time you are building up a detailed change history of all your metadata — line by line, file by file, author by author — far beyond anything provided by Salesforce's built-in change tracking mechanisms such as setup audit trail, last modified fields or even source tracking.
Comparing environments
By regularly flowing changes from your Salesforce orgs into their Git branches, those branches become up-to-date copies of the metadata in the orgs. This enables you to easily compare them to visualize metadata differences between your environments. Most Git providers include branch comparison features in their web interfaces. There are also many great desktop apps that provide even more sophisticated comparison features.
Comparing a component across two environments without Git conceptually looks something like this:

It's not possible to know whether the required property was set to false in one environment, or set to true in the other, because we are looking at a mere A-to-B diff, also known as a two-way compare.
Two branches in Git typically share a common ancestor (the point before the two branches started diverging), which makes comparisons much more powerful. Rather than just show you the current difference between the two, Git can show you the what changed in one compared with what changed in the other (known as a three-way compare) which gives you much more clarity and insight:

In this scenario we can see the common ancestor (also known as the base version) in the middle. It's clear that the required property remained false in one environment, and was set to true in the other.
Safe merging of changes
Many other Salesforce deployment and DevOps tools move changes between environments using simple copy-paste semantics. Even if this includes a comparison step, you are forced to manually determine whether a difference on a given line is the result of a change in the source org, a change in the target org, or changes in both. This can be a very difficult determination to make without knowing exactly what happened in each org over time. There is a high risk that changes in one org end up overwriting changes in another org (a phenomenon known as clobber) without anyone knowing.
For example, consider the following two-way diff while deploying from the left environment to the right:

What do we actually want to deploy here? Were all these properties changed in the environment on the left, or were some of them changed in the environment on the right? There is no way to know, so how can we safely proceed with this deployment without inadvertently risking clobbering changes made in the environment on the right?
In OrgFlow, by contrast, all metadata changes are flowed between environments by merging the commits in a source branch with the commits in a target branch. Because Git knows what changed in each branch since their common ancestor, it can carry out a three-way merge to combine those changes, even when the same component was changed in both environments:
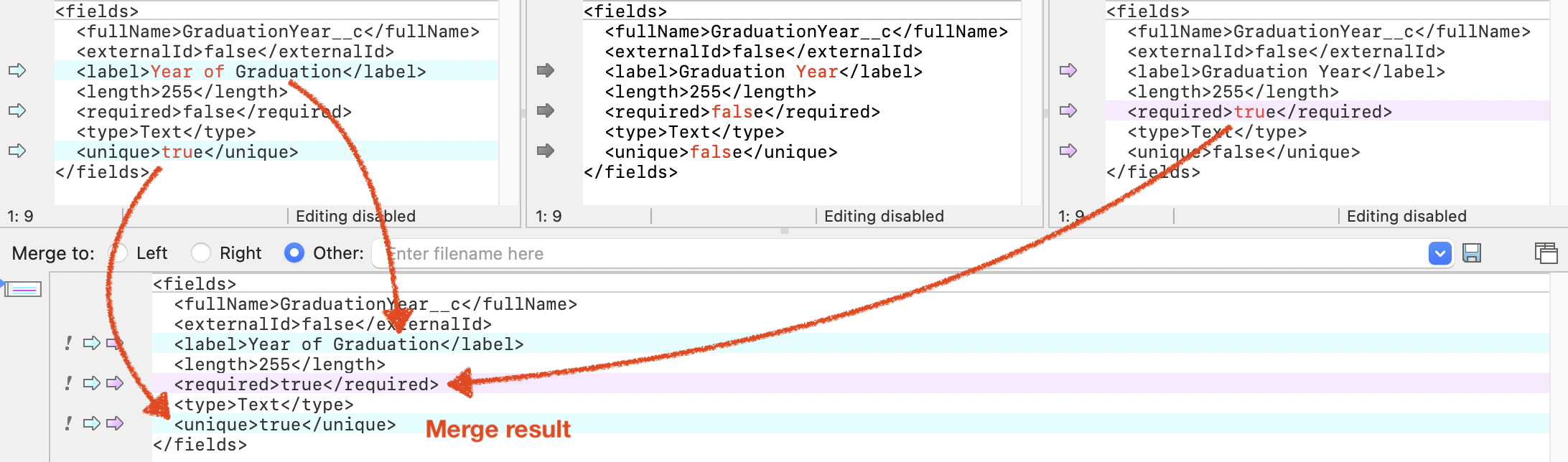
Notice the common ancestor (the base version) in the top middle field. Git can use it to determine that the label and unique properties were changed in the environment on the left, while the required property was changed in the environment on the right. Because all these changes are on different lines, by determining each change against their common ancestor, Git can automatically and safely combine the two sides, so that no changes from either of them are lost.
Conflict detection and resolution
Using the three-way merge process described above, Git can automatically reconcile and combine different changes made to the same component in different environments. Sometimes, however, those changes conflict with one another by changing the same lines in the metadata source in different ways — this is known as a merge conflict, and Git detects and raises such conflicts whenever it cannot safely merge changes.
When merge conflicts are detected during a managed worker job, processing is paused and an inquiry is conducted, waiting for a user on your team to resolve the conflicts before processing can continue. The merge conflict resolution interface in OrgFlow Web visualizes merge conflicts graphically and makes them easy to understand and resolve.
When merge conflicts are detected during a CLI job, processing is paused and a prompt is shown offering the user several options for resolving the merge conflicts, including using external third-party merge tools. You can also merge between branches outside of OrgFlow, either using the merge features of your Git provider or using merge features in desktop Git tools.
Collaborative review and validation using pull requests
By keeping your Salesforce metadata in a Git repository, you automatically gain the ability to work with pull requests. A pull request is a proposal to merge a set of changes from one Git branch into another. It packages up the resulting delta so that teammates can review, discuss, and validate the changes before they become part of the target environment.
Pull requests can also trigger automated CI pipelines that do things like static code analysis and validation deployment of the proposed (merged) changes into the target org, to catch issues early. Most commercial Git providers include pull request functionality.
Working with metadata locally
Once you have a Git repository with branches that are up-to-date copies of the metadata in your Salesforce orgs, metadata becomes extremely easy to work with outside of Salesforce, using tools like Visual Studio Code and the Salesforce Extension Pack. For example, you can simply clone your repository to your local computer, check out an environment branch, make code or metadata changes using Visual Studio Code, commit the changes and push them back to your repository.
Backup, snapshots and rollback
By regularly flowing changes from your Salesforce orgs into their Git branches, you are continuously maintaining a current and historical backup of your Salesforce metadata, which gives you the ability to restore your Salesforce org's metadata to an earlier point in time. It is technically possible to restore your org's metadata to any commit in its backing Git branch, but to make point-in-time metadata restore even easier, OrgFlow also records snapshots and provides built-in functionality for rolling back environments to a specific snapshot of your chosing. Snapshots and rollbacks make the point-in-time restore process more seamless by including environment state stored in OrgFlow's cloud in addition to the metadata stored in the Git repository.
CI/CD platform integration
Having your Salesforce metadata in a Git repository provides a natural integration of your Salesforce metadata change flow into CI/CD platforms like GitHub Actions and Azure DevOps, where Git repositories play a central role. This opens the door to a universe of other popular tools and services to take your Salesforce DevOps even further, such as static code analysis, translation management, data seeding, scratch org management, Apex test result analytics, or integration with Slack or Microsoft Teams.
Partial success and eventual consistency
Git makes possible two of OrgFlow's most powerful features: partially successful flow out and eventual consistency. Your Git repository provides an immutable version history of every included metadata component. When a metadata component cannot be deployed to a target org, being able to refer to the past version of that component when it was known to be in sync allows OrgFlow to keep track of the undeployed differences, and merge those with further changes to the component.
Repository structure
By default, OrgFlow uses a directory structure similar to the following for storing Salesforce metadata and other files in your Git repository:
text
<repository root>
├── .orgflowinclude
├── src
│ ├── unpackaged
│ │ ├── classes
│ │ ├── objects
│ │ ├── workflows
│ │ ├── <...>
│ │ └── package.xml
│ ├── PackageA
│ └── PackageB
└── <other content>The .orgflowinclude file on line 2 contains the include specs that tell OrgFlow which subset of your Salesforce metadata should be monitored for changes, synced to and from the repository and flowed between environments.
The src directory on line 3 contains the actual Salesforce metadata. The name of this directory can be customized, or it can even be omitted completely (see the metadata path section below). The contents of this directory constitute a valid archive in standard Salesforce metadata format, and can normally be understood and processed by other third-party tools.
Don't use the src directory for other purposes
You must not story any other files in this directory that are unrelated or don't form a valid part of the metadata archive. Doing so may cause OrgFlow or Salesforce to misinterpret the contents of the directory, which may lead to data loss.
The src directory contains one subdirectory per metadata package, including an unpackaged directory on line 4 which contains any metadata in unpackaged space. In the majority of cases, unpackaged will be the only directory here, as including metadata in managed packages in the flow is very rare, and can be more easily achieved by including namespaced metadata in unpackaged space instead (see namespaces for more information).
Each package contains a package manifest in the form of a package.xml file shown on line 9. See the package manifests section below.
Alongside the include specs and metadata, you can keep whatever else you want in the repository as long as nothing interferes or conflicts with the .orgflowinclude file or the src directory. Common examples of other repository contents include CI/CD pipelines (for example GitHub Actions workflows inside a .github/workflows directory), tooling configuration (for example a .vscode/settings.json file), a .gitignore file at the root of the repository, and documentation.
Using your repository outside of OrgFlow
It's important to understand that OrgFlow does not require exclusive control over your Git repository. We encourage you to also directly interact with your Git repository alongside OrgFlow as needed. For example, you should feel free to:
- Manually commit changes to OrgFlow's environment branches (for example using an IDE such as Visual Studio Code)
- Create branches other than those used by OrgFlow, and even merge those into OrgFlow's environment branches
- Store files in the repository other than the Salesforce metadata stored by OrgFlow
OrgFlow has been designed to coexist with other activity and contents in the repository. Files outside OrgFlow's configured metadata directory will be left alone by OrgFlow. Metadata changes committed and pushed outside of OrgFlow will be incorporated into the change flow just like changes made in your Salesforce orgs by your team's developers and admins.
Never remove commits from OrgFlow environment branches
OrgFlow needs the full commit history of each environment's Git branch. If you remove commits that might be referenced in OrgFlow's state store (for example by force pushing to an environment branch, or by squashing commits when merging between two environment branches) then you run the risk of removing commits that OrgFlow depends on in order to facilitate things like merging changes during flow in.
This can lead to data loss, unexpected behavior and errors such as committish to branch from '<commitHash>' does not exist in repository (shown when a commit hash that has been recorded in OrgFlow's cloud no longer exists in the environment's backing Git branch).
To recover from this situation, you will need to run a flow in with force mode enabled, which will revert any undeployed changes in the environment's branch.
Version control settings
You can customize some aspects of how your metadata is version controlled using the version control settings in your stack.
Metadata path
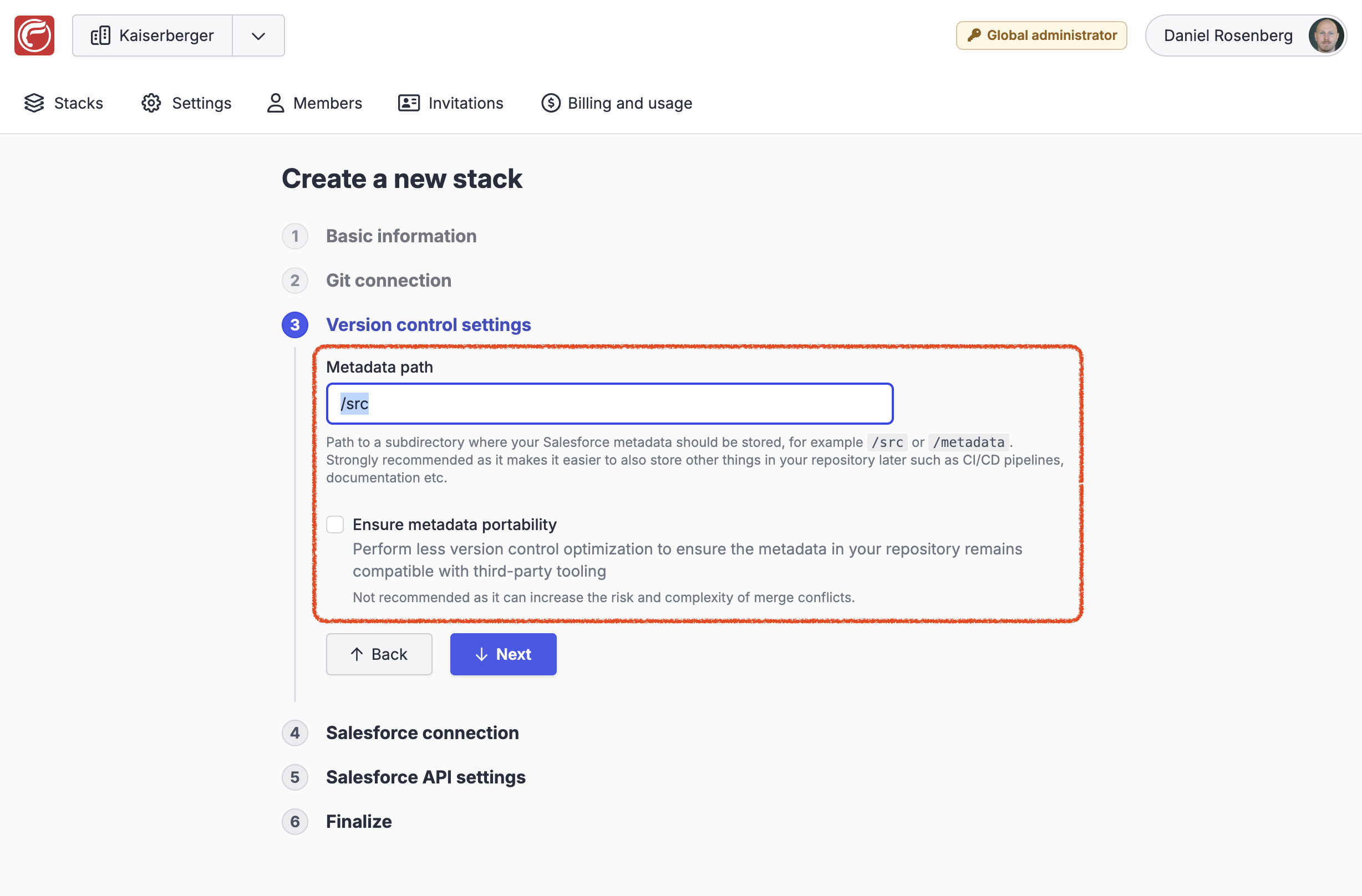
This setting lets you configure the path to a directory (relative to the repository root) where OrgFlow should store Salesforce metadata. The directory will be created by OrgFlow during flow in, if it doesn't already exist.
This setting defaults to src when creating a new stack, but it can be set to any valid directory path, or even set to empty to store metadata directly in the repository root. It is strongly recommended to use a subdirectory, however, as it makes it possible to also store other things in your repository later, such as CI/CD pipelines, documentation etc.
Ensure metadata compatibility
By default, OrgFlow optimizes some types of metadata for more efficient version control.
One example of this is the WaveDataflow metadata type. The metadata API sometimes returns components of this type in a rather strange format where the actual WaveDataflow JSON document is itself treated as a string, JSON-encoded and then wrapped as the first element inside a JSON array, followed by an additional NULL element in the same array. This makes the component effectively impossible to version control because, as a single string, they cannot be broken onto multiple lines, and therefore they cannot be nicely formatted, branched and merged; every change somewhere in the WaveDataflow component is on the same line. To mitigate this, OrgFlow "unwraps" WaveDataflow components for more effective version control, and "rewraps" them before deploying to a Salesforce org.
Enabling this setting instructs OrgFlow to optimize for maximized compatibility with third-party tooling instead, at the expense of efficient version control. We recommend that you only use this setting if you experience issues with compatibility with third-party tooling, as it can increase the risk and complexity of merge conflicts.
Configuring settings
The version control settings can be provided when creating a new stack, as shown here:
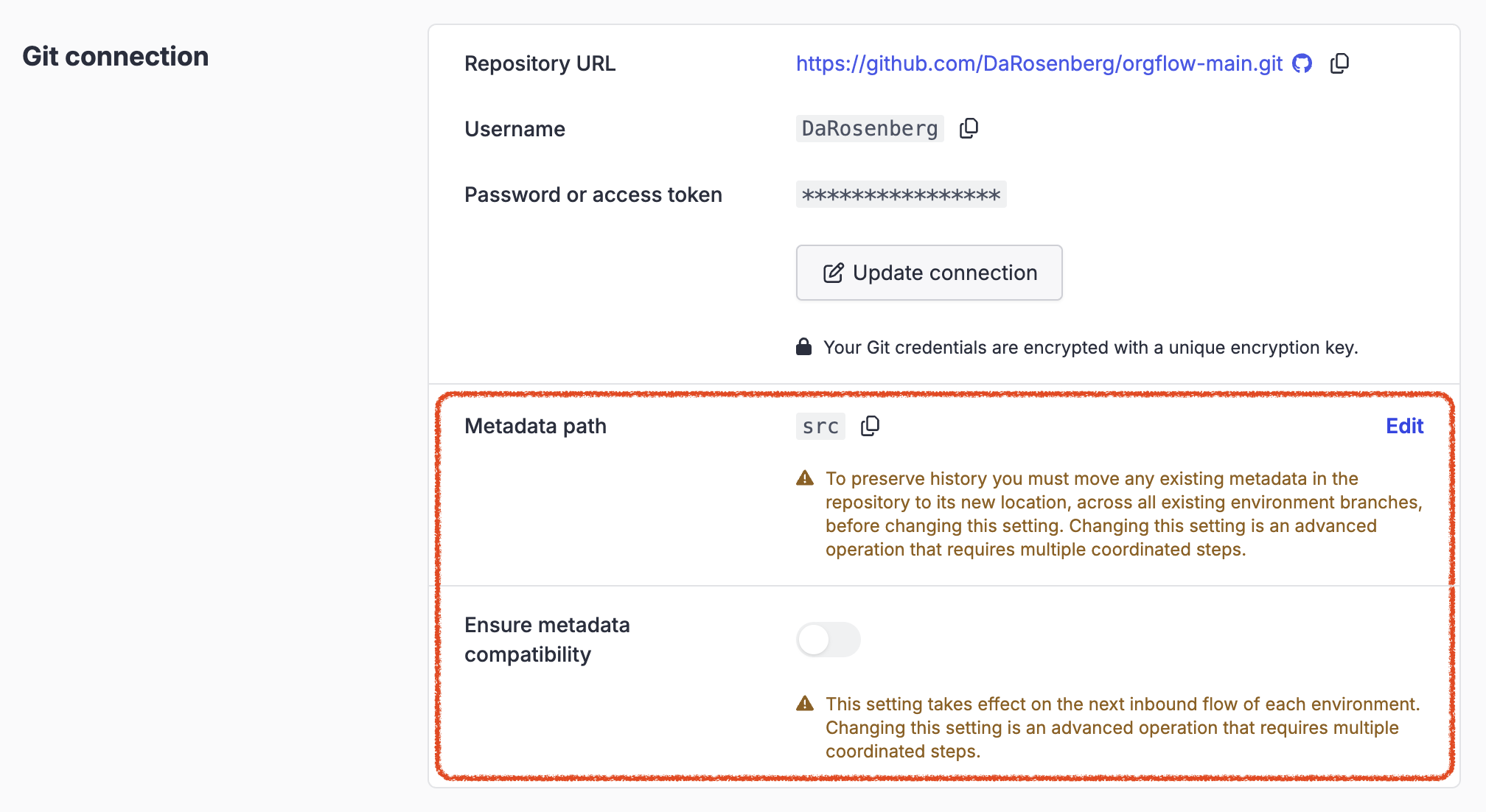
They can also be modified on an existing stack under the Git connection section of the stack settings page, as shown here:
Caution when changing version control settings on an existing stack
Changing the version control settings on an existing stack is an advanced operation that requires multiple coordinated steps. In particular, changing the metadata path must be done with great caution. To preserve history you must move any existing metadata in the repository to its new location across all existing environment branches before changing this setting, and you must ensure that no flow operations occur in the stack in the meantime.
Format
OrgFlow stores metadata in your repository using Salesforce metadata structure and format.
Salesforce also supports a newer and more decomposed storage format for metadata known as source format. Source format was introduced along with the Salesforce DX project structure, and is primarily used by the Salesforce CLI. It was designed to facilitate easier version control by breaking down potentially large components (such as objects) into smaller files.
OrgFlow does not currently support the source format. However, most of its version control benefits are instead achieved using normalization.
Normalization
Salesforce metadata retrieval is not fully deterministic. Retrieving the exact same metadata from the same org twice in a row can result in different retrieved metadata archives, primarily because some elements are ordered arbitrarily. This behavior makes effective version control extremely challenging, often even infeasible, because neither users nor Git itself are able to distinguish real differences from differences only in element ordering, resulting in frequent merge conflicts that can be practically impossible to resolve.
To mitigate this, OrgFlow performs a process known as normalization on your Salesforce metadata. This is always done immediately after retrieving metadata from a Salesforce org, as well as after merge operations and other operations that may potentially have modified the metadata.
Normalization involves the following steps:
- Formatting metadata XML and JSON with consistent indentation
- Ensuring all metadata XML files have consistent prologues/XML declarations
- Ensuring XML elements are ordered deterministically
This process prevents insignificant changes (i.e. changes in formatting or element ordering which produce no actual differences in the semantic meaning of the metadata) from entering your Git repository, and helps eliminate "phantom" merge conflicts.
Normalization is performed automatically by OrgFlow whenever required. There is also an md:normalize command in the OrgFlow CLI which allows you to normalize any metadata archive on your local file system on demand, which can be helpful in advanced automation scenarios.
Case-only renames
Metadata in a Salesforce org have roughly case-insensitive but case-preserving semantics:
- Two item names in the same scope (e.g. two fields on the same object) cannot differ by case alone
- Items being deleted (through
destructiveChanges.xml) are matched case insensitively - Items being modified are matched case insensitively, but will have their API name updated to the new case
- Items being added are added with the case specified
This means metadata items in a Salesforce orgs can be renamed to change only the casing of their name. For example, it's possible to rename an Apex class from myclass to MyClass. Such changes are referred to as case-only renames and, when committed to your Git repository, can cause issues later on when your repository is cloned to and used on devices with case-insensitive file systems (the default on both macOS and Windows).
Long-term risks of case-only renames
While case-only renames may seem harmless, allowing them in Git repositories without careful consideration can creates several significant long-term problems:
Repository accessibility and checkout failures: Case-only renames create commits that can become "un-checkoutable" on case-insensitive file systems. When two files like
myclass.clsandMyClass.clsboth exist in Git history (either simultaneously or over time) users may encounter checkout errors, silently merged files, or perpetually "dirty" working directories where the index and filesystem disagree. This makes certain commits or branches effectively inaccessible to some team members.Persistent merge conflicts and cross-platform failures: Merges involving case-only renames fail unpredictably across platforms. When one branch edits
myclass.clswhile another renames it toMyClass.cls, case-insensitive systems encounter path collisions that case-sensitive systems handle cleanly. This creates scenarios where everything works fine in OrgFlow Web and managed worker jobs, but developers can't merge locally on their macOS and Windows computers, potentially breaking team workflows.Repository degradation over time: Allowing case-only renames often creates a compounding problem — the practice spreads, directories may get renamed by case (especially painful), and history may become harder to follow. This can create a permanent maintenance burden on every clone, checkout, and merge operation, potentially rendering portions of repository history practically inaccessible to contributors on some platforms.
Enabling case-only renames support
For the reasons outlined above, OrgFlow defaults to blocking case-only renames from being flowed in from Salesforce into your Git repository. This is the safest default, because it allows the repository to be cloned to and used on team members' computers, even in teams working primarily on macOS and Windows computers.
However, for admins and developers who focus primarily on making customizations in Salesforce orgs, and for whom version control implications may not always be top-of-mind, it can be a burden to have to remember to not make case-only renames, and unwelcome friction to have such renames be rejected by OrgFlow and effectively block the team's DevOps workflow.
For that reason, it's possible to configure OrgFlow to allow case-only renames.
Prepare before enabling
Before enabling this setting, ensure that all team members who will work with the repository on their local devices understand the implications, and have configured their environments appropriately (see below).
If your team needs to allow case-only renames, you can enable this in your stack settings:
- Navigate to the Stack settings page
- Find the Allow case-only renames toggle in the Git connection section
- Enable the toggle
Working with case-only renames enabled
If you enable case-only renames for your stack, you and your team must take special care before cloning and working with the repository on computers where file systems are case-insensitive by default. The recommended approach is to create a case-sensitive storage volume or directory specifically for your Git repository. This ensures that case-only renames can be properly tracked and preserved.
On macOS, use the Disk Utility app to create a new storage volume (make sure to choose APFS (case-sensitive) as the format). The new volume can be used at its default mount point, or optionally symlinked into a more convenient location. Your Git repository can then be safely cloned into this location.
On Windows 10 (version 1803 and later) and Windows 11, create a new empty directory and use the fsutil file setCaseSensitiveInfo [directoryPath] command to configure that directory as case-sensitive. Your Git repository can then be safely cloned into this directory.
Package manifests
For every metadata package stored in your Git repository — including the unpackaged directory — OrgFlow maintains an up-to-date package.xml file, also known as a package manifest. The package manifests lists all metadata components in the package by type.
OrgFlow does not use the package manifests itself, but it maintains them and ensures they are an accurate and up-to-date declaration of all the metadata in your repository. This can help when working with your metadata in local tools, and also improves interoperability of the repository with external third-party tools and services.
Package manifest generation is performed automatically by OrgFlow whenever required. There is also an md:manifests command in the OrgFlow CLI which allows you to create or update package manifests in a metadata archive on your local file system on demand, which can be helpful in advanced automation scenarios.